
Introdução
A tabela de espalhamento, também conhecida como hash table, é uma das estruturas de dados mais importantes da ciência da computação. Ela permite armazenar e acessar informações de forma extremamente eficiente, geralmente em tempo constante (O(1)), desde que seja bem implementada. Seu uso é comum em algoritmos, bancos de dados, compiladores, sistemas de cache e em praticamente qualquer aplicação que necessite de buscas rápidas.
Definição de tabela de espalhamento
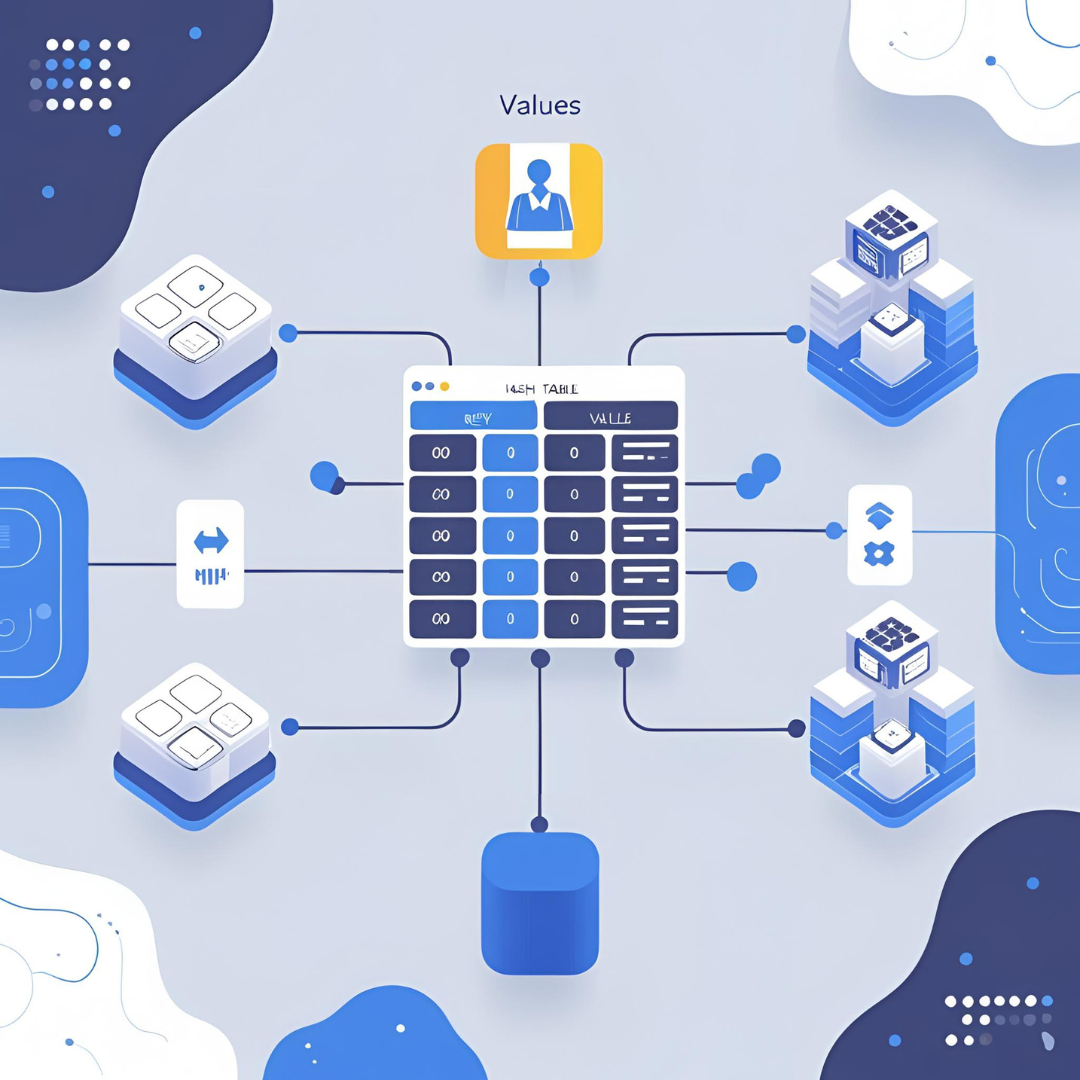
Uma tabela de espalhamento é uma estrutura de dados que utiliza uma função de espalhamento (hash function) para mapear chaves (keys) a posições em uma tabela, onde ficam armazenados os valores correspondentes.
- Chave (key): identificador único para acessar um dado.
- Valor (value): informação associada à chave.
- Função de espalhamento: responsável por transformar a chave em um índice da tabela.
O objetivo principal dessa técnica é reduzir o tempo de busca, inserção e remoção, evitando percorrer toda a estrutura.
Operações em tabelas de espalhamento
As principais operações realizadas em uma tabela de espalhamento são:
- Inserção: adiciona um par chave-valor.
- A função de espalhamento calcula o índice e insere o valor nessa posição.
- Busca: encontra o valor associado a uma chave específica.
- Geralmente ocorre em tempo constante, desde que não haja muitas colisões.
- Remoção: exclui um par chave-valor.
- Pode marcar o espaço como vazio ou reorganizar para evitar buracos na estrutura.
Colisões e tratamento
Um dos principais desafios das tabelas de espalhamento é a colisão, que acontece quando duas chaves diferentes geram o mesmo índice. Existem métodos para lidar com isso:
- Encadeamento separado (separate chaining): cada posição da tabela aponta para uma lista encadeada de elementos que caíram naquele índice.
- Endereçamento aberto (open addressing): procura-se a próxima posição disponível seguindo um padrão (linear, quadrático, duplo hashing).
Otimização de tabelas de espalhamento
Para manter o desempenho ideal, é necessário ajustar a implementação:
- Boa função de espalhamento: distribui as chaves de forma uniforme, evitando concentrações.
- Controle do fator de carga (load factor): relação entre número de elementos e tamanho da tabela.
- Redimensionamento (rehashing): quando a tabela fica cheia, aumenta-se seu tamanho e recalculam-se as posições.
Usos avançados e aplicações
As tabelas de espalhamento têm aplicações práticas em diversos cenários, como:
- Compiladores: armazenamento de variáveis e funções em tabelas de símbolos.
- Sistemas de cache: armazenamento rápido de dados temporários.
- Banco de dados: indexação para busca eficiente.
- Segurança: verificação de integridade de dados com funções hash criptográficas.
- Jogos e IA: busca rápida de estados e movimentos.
Conclusão
A tabela de espalhamento é uma ferramenta poderosa para otimizar o acesso a dados, sendo uma das estruturas mais utilizadas na programação. Quando bem projetada, garante velocidade, eficiência e escalabilidade, tornando-se indispensável para sistemas que exigem desempenho.